前面兩篇文章中,咱們已經學習完索引的核心觀念以後,接下來咱們學學在使用時有那些的優質的方法與注意事項。
本篇文章分為以下幾個章節 :
索引不是聖杯,它是雙刃刀,用的好上天堂,用不好下地獄。基本上資料庫的索引幾乎可以影響一個系統的 50% 以上的性能。
索引可以加快查詢速度,但注意它是以空間換取時間。
基本上它使用的資源如下 :
所以當你索引越多時,你所需要的記憶體與維護索引的 cpu 運算就需要越多。
explain 這個指令可以讓你知道你下的 sql 語句是否有命中索引。
EXPLAIN SELECT * FROM user_no WHERE name = 'mark';
=====================================================
id: 1
select_type: SIMPLE
table: user
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
如上範例的 type 與 key 這兩個欄位,它有很明確的說明使用到 pk,也就是直接使用 clustered Index 索引樹來找資料。
詳細的欄位說明建議看以下兩篇,我覺得它已經說明的很清楚了,這裡你只要知道,explain 可以幫助你解析 sql 的性能,然後你根據結果,來進行你的索引或 sql 改善。
在 mysql 的世界 ( 其中資料庫我不確定 ),不是建了索引,且下的 query 正常就會一定會使用。
例如咱們有以下的索引
table : user
field: name, sex
index: {sex}
然後你執行下面的 sql :
SELECT * FROM user WHERE sex = 0 ( 0 代表女生 )
那這時會不會用索引呢 ?
答案是不一定,如果大部份的值都是女生,那 mysql 會用全掃,如果大部份值為男生,那 mysql 會用索引。
首先第一件事情就是定義需求或是預測,來決定那些欄位『 可能 』需要建立索引,等有候選欄位後在進行下一個步驟。
找出那些欄位較常需要拿來 query
基數就是指這個欄位的值的可能性。
像假設某個欄位是存性別,也就是說只有『 男 』與『 女 』,那就代表這個欄位基數很小,這時就不建議建立索引。
為什麼呢 ?
因為如果建了,mysql 也不太會使用。你想想,一個欄位只有男與女兩種,那這時你要找女的,你覺得全掃一個一個找比較快,還是先用索引找出所有女的 pk,然後再去 clustered Index 抓資料呢 ?
可以看看下圖 1 所示,很明顯用全掃反而會比較快,所以這時 mysql 會直接選用全掃,所以你建立的索引會完全用不到。
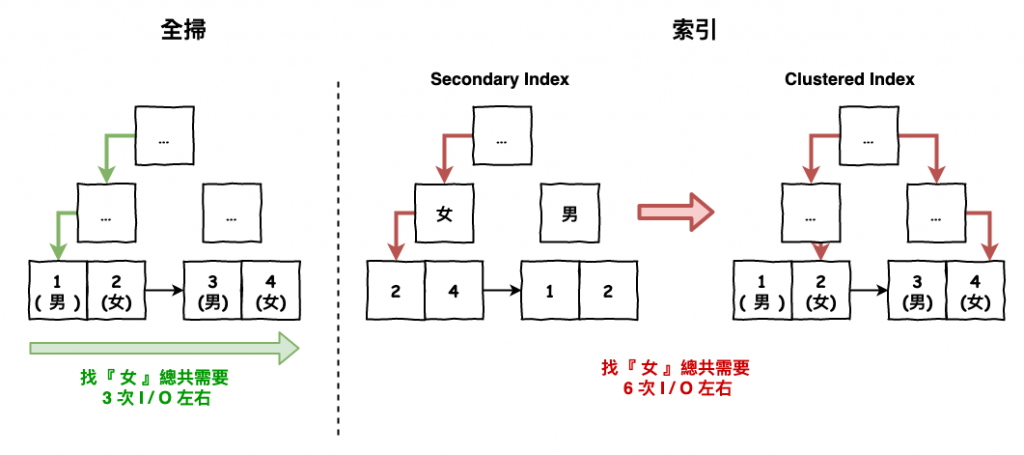
圖 1 : 全掃與索引在基數小時的比較圖
備註:
在系統建立開始預測預期基數事實上不一定很準備,除非是一些很明顯用意的欄位,例如性別這種,不然大部份的情況預測可能都會有誤差,因此這裡建議在一定的固定時間,來分析一下資料庫裡的索引資料,計算一些實際上的基數,來決定要不要補索引,或是移除索引。
咱們通常可以使用以下指令,來在已運行的資料庫中,來看看某個欄位的基數大概是多大 :
SELECT COUNT(DISTINCT {field}/COUNT(*))
假設咱們有 1000 筆資料,然後這個欄位是性別欄位,那它的數字應該為 :
2/1000 = 0.002
這個數值越接近 1,代表越有建立索引的價值。
基本上就是以下三種選擇 :
假設咱們有一個連合索引如下,由三個欄位 a、b、c 組合而成,而事實上在使用時,咱們可以將它想成有下以三種組合,當然這不代表他有存放三顆樹。
{a, b, c}
=
{a}
{a,b}
{a,b,c}
然後根據三序的組合,使用上有個準則。
有用到最左邊的欄位的才能使用連合索引
以上面連合索引範例為例,下面為使用的 sql 是否會用到索引的情境。
SELECT * FROM Table WHERE a = ? ( good 索引 )
SELECT * FROM Table WHERE a = ? AND b = ? ( good 索引 )
SELECT * FROM Table WHERE b = ? AND a = ? ( good 索引 )
SELECT * FROM Table WHERE b = ? ( bad 全掃 )
SELECT * FROM Table WHERE c = ? ( bad 全掃 )
SELECT * FROM Table WHERE b = ? AND c = ? ( bad 全掃 )
首先有個重點要記得,如下圖 2 使用『 年齡 』所建立的索引 :
索引本身就是有排序的
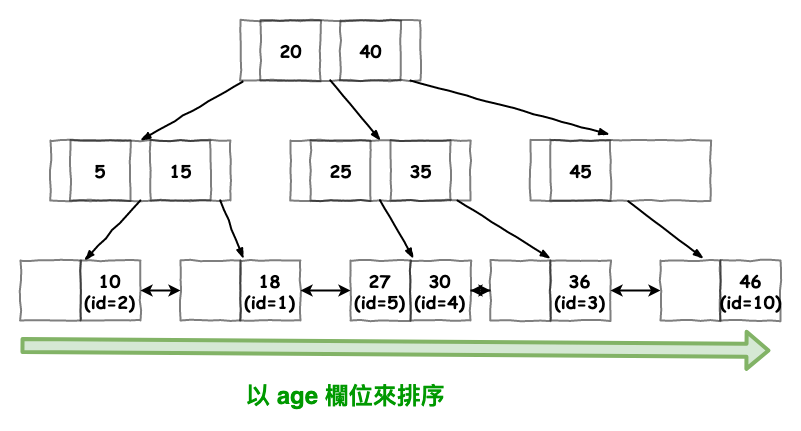
圖 2 : 以年齡建立的索引
這也代表如果要進行排序,儘可能的直接使用它,而不要讓資料庫另外開空間,來排序它。
索引欄位: { age }
SELECT * FROM user WHERE age <= 30 ORDER BY age; ( good 索引 )
SELECT * FROM user WHERE age <= 30 ORDER BY name; ( bad using filesort )
其中上述範例中 bad 的 filesort 就是代表 mysql 需要另外使用記憶體來排序,這可以在 explain 時看到。
它也有排序。
連合索引是以最左邊的欄位排序
所以假設你有一個索引為 :
{ age, name }
那它預設就會以 age 來排序,如下圖 3 所示。
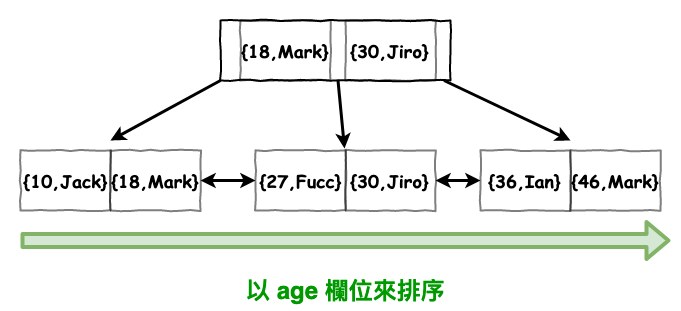
圖 3 : 連合索引排序
簡單的說,你有以下三欄位,a、b、c 然後請不要想說讓性能好一點,來個所有組合的索引。這樣不但多化了不少空間建 b+ 樹,而且還會讓 mysql 優化器選錯索引。
a、b、c
a、c、c
b、c、a
b、a、c
c、a、b
c、b、a
這個問題,主要是從下面這篇文章得知,而且自已測試了以下,還真的是這樣,詳細的實際過程與結果,請連到下面的連結自已去看看。
SELECT * FROM user WHERE age != 20 ( bad 全掃 )
SELECT * FROM user WHERE age <> 20 ( bad 全掃 )
SELECT * FROM user WHERE age NOT IN(20) ( bad 全掃 )
如果在 name 有建立索引,那有下面這種 sql 會變全掃。
SELECT * FROM user WHERE name like '%-Mark' ( bad 全掃 )
索引欄位: {age}
SELECT * FROM user WHERE age = 18 OR name = 'C-Ian'; ( bad 全掃 )
索引欄位: {age},{name}
SELECT * FROM user WHERE age = 18 OR name = 'C-Ian'; ( good 索引 )
但是如果是用 and 則反之。
索引欄位: {age}
SELECT * FROM user WHERE age = 18 AND name = 'C-Ian'; ( good 索引 )
索引欄位: {age}
SELECT * FROM user WHERE age/2 = 18; ( bad 全掃 )
SELECT * FROM user WHERE age = 18*2; ( good 索引 )
下面簡單以 rand() 這方法來說明,當你使用它時,它就是一定跑全掃
SELECT * FROM test.user where age >= RAND(); ( bad 全掃 )
因為這樣可能會讓你所建立的『 覆蓋索引 』失效,導致要先至 secondary index 查找再去。
clustered Index 抓資料。
索引欄位: {name}
SELECT * FROM user; ( bad 會走 secondary index 再至 clustered Index )
SELECT name FROM user; ( good 只會走 secondary index )
當你確定資料量非常小的情況下使用還行,但是資料量大時,你資料庫一定會倒。如果真的要做請把資料拉到應用層在做,資料庫真的非常的忙。
SELECT * FROM test.user where age <= 18 ORDER BY RAND(); ( bad 會需要耗費空間排序 )
本篇文章中咱們學習到了一些設計優質索引的方法與流程,並且也簡單的列出一些雷區,關於這邊的雷區,順到來提一下 『 ORM 』這個東西。
orm 基本上是一個將資料庫操作封裝成 model 化的技術,簡單的說你要查詢某樣東西那會如下操作 ,比較白話文就是你不需要自已寫 sql。
// SQL
SELECt * FROM user WHERE age = 18;
// ORM (以 laravel eloquent model 為範例)
$user = User::where('age', 18)->get();
當你使用了 orm 後就不在需要寫 sql,而是以 model 的角度來操作它,這樣的好處如下 :
而缺點就在於,你需要多耗費資源運算來處理。
不過我事實上是屬於佔在 orm 這一派的人,雖然這 30 天的文章是以高性能為主。
主要的原因有幾點 :
如果以追求高性能系統來看,的確是以 sql 為主沒錯,但是高性能不代表是一個好的系統,好的系統是需要平衡的,而我們要學會平衡的其中一個條件也就是理解何謂高性能 ( 對這是繞圈子 )。
好的系統是需要平衡的
最後說一下,雖然哥追求高性能,但是我是個願意為了減少雷包風險,而犧牲點性能的人。因為維護成本真的高,尤其公司越大,維護成本越高,如果整間公司都是追求高性能而不管維護性,我只能保祐後人的身體健康。
Hi 馬克:
感謝你的分享,此系列文很詳細又很精采.
但我對於雷區 2 : 用 like 有索引也會變全掃這個部分我認為是這樣.
下面這個like寫法的確不會跑索引
SELECT name FROM user WHERE name like '%-Mark' ( bad 全掃 )
但如果是寫成下面這個寫法%在後面且name有建立索引就會跑了.
SELECT name FROM user WHERE name like '-Mark%'
所以我個人建議可以寫成
用
like且%在前面就算有索引也會變全掃

嗯我改一下 ~ 我這樣寫的確會讓人誤會以為只要使用 % 就會全掃 ~ 感謝你 ~
您好
剛剛去試了SELECT COUNT(DISTINCT {field}/COUNT(*))
這段SQL語法
但是出現錯誤
嘗試了一下
最後得出括號應該放在前面
SELECT COUNT(DISTINCT {field})/COUNT(*)
不知道是我的問題抑或是版本有差還是您這邊標記錯誤呢

